作者|苏奕
“人均月薪两万、本科以上学历、直通百度字节。”
有些许荒凉的年底招聘市场,在最近的短短一周之内,突然冒出了一大批“AI数据标注员”的岗位,正在火热招聘中。
据‘自象限’搜索,这些岗位不仅有百度、字节、京东、滴滴、美团等“梦中情厂”,工资月薪十分亮眼,都在1万到2万元之间,且发布时间很短,都在1周到1个月之间。
除了新以外,岗位招聘显然非常急迫。据招聘软件显示,HR们都异常活跃,一天24小时几乎全程在线,日均回复次数在十次以上,隔几分钟就回复一次。
“最近只要一上线,有关AI数据标注员的招聘消息就疯狂弹,重复地弹。”不少正在求职的人向【自象限】反映,“上次这么疯狂的打招呼,感觉还是主播招聘。”
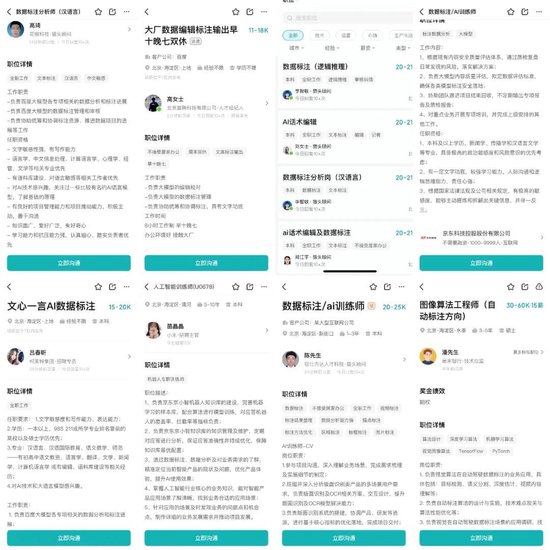
▲图源Boss直聘截图
招聘的火热,很难不让人想到大厂的大模型之战。
不过,据‘自象限’观察,“AI数据标注员”招聘不是由这些大厂直接操办,而是通过猎头公司来负责招聘。岗位的名字也是五花八门,有“数据标注”、“AI话术编辑”、“数据标注分析师”、“标注员”、“AI训练师”等等。
虽然叫法不同,但关于这些岗位的职能描述却大差不差,据招聘软件信息显示,其中很大一部分岗位跟现下大热的大模型有关,入职的数据标注员们的日常工作包含,大模型的编辑校对、大模型的数据标注管理、大模型的内容质量评估等。
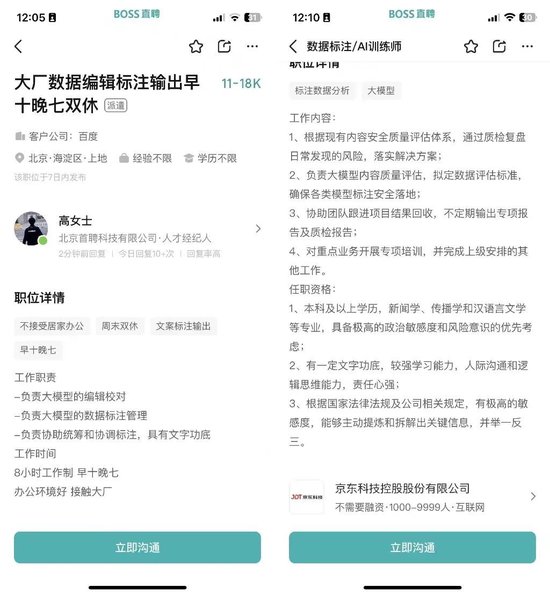
▲图源Boss直聘截图
‘自象限’向多位招聘HR进行了咨询,“工作的主要内容是对文心一言大模型回答结果的分析和判断,工作的地点在百度科技园。”有猎头回复道。
高薪资待遇、挂钩大模型、大厂哄抢……有求职者看到了机会,“大模型的风,要带动新一批大厂人扎根了,普通人的机会来了吗?”
但事实上,时间紧、任务重的岗位招聘,要求却并不算低,基本学历要求本科起步,985、211优先本科和硕士优先,在具备语言学、中文信息处理、计算语言学、文学等相关专业背景的同时,还得对一些AI技术的原理有了解。
花椒科技告诉我们,面试的基本流程是,“简历初筛-发笔试题-笔试题通过一轮面试-直接发offer-培训”,在学历方面,猎头强调“必须得是一本才行,211/985优先”。
严格准入门槛,招聘软件上神秘的“AI数据标注员”背后,藏着大厂的大模型棋局。

我,给大模型当“考官”
月薪两万
历时一个多月的面试,中文系毕业的罗文(化名)最终敲定了自己的offer——百度文心一言的AI数据标注员。连她自己都不敢相信,一个纯技术小白现在的日常竟然是给大模型当“考官”。
“毕业三年,没有任何AI经验,转行涨薪,幅度近50%,月薪在9k-15k左右”,罗文告诉我们。
坐在两台电脑前,罗文每天的主要工作有两项:一是做题,直接给大模型进行“填鸭式”教育;二是给文心一言当“判官”,评判给出的答案对不对、好不好。
所谓“填鸭”就是强行把写好的答案喂给大模型,这样的好处就是从数据源上不会出错,以此来提升大模型的训练效果。罗文告诉‘自象限’,数学题、常识题、作文题她都做过,但这还远远不够,“理论上,越专业越好,比如我擅长文学领域,那就专攻文学题,有的同事专业是医学,那就做医学问答题”,罗文道。
罗文的话已经在一些社交平台得到验证,有人曾发布帖称,“急需招募金融专业人员,有偿给文心一言答题,一天30多道,每道题价格在1.5-2.4元。”

▲图源社交媒体平台小红书截图
另一项工作就是给大模型当“判卷老师”,就像学生考试一样,每天大模型会生成各种问题的答案,罗文就需要承担老师的角色,判断其生成的答案与题目是否一致,答案是否正确。
若遇到诸如作文一类没有标准化答案且开放性的问题时,则需要评判答案的好坏,比如,系统会随机给一组数据,包含1个问题和3个回答。罗文需要先标注出这个问题属于什么类型,随后给3个回答分别打分并排序。分数区间为0-5分,如果打分低于3分,还要标注出具体原因,例如“答非所问(0分)”、“严重跑题(1分)”、“存在逻辑问题,存在事实性错误,比例较小给2分”等。
这个工作虽然看上去并不难,但却异常重要,甚至可以从外包直通大厂的机会。据上述猎头告诉我们,“虽然合同跟我们猎头公司签,但是还是有六分之一的几率转正,进入百度集团”。这或许也是严格控制学历的原因。
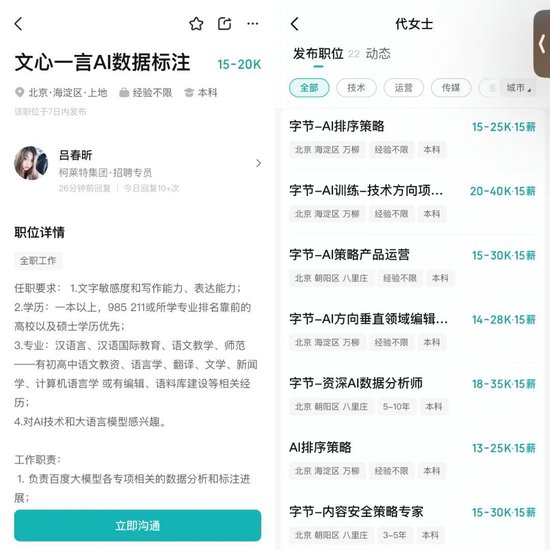
▲图源Boss直聘截图
为此,‘自象限’也了解到,由于百度地图的数据标注,有稳定的地图业务需求及自动驾驶模型、算法模型的训练需求,所以对数据标注的质量要求更高,的确搭建了专门的数据标注团队。
市场上对“罗文”的需求,不止大模型公司。据‘自象限’统计,目前,市面上的数据标注岗位大致分为两种。
一种以NLP(自然语言)为主要方向,百度、字节、京东、美团等一批大模型科技公司一拥而上,给自家大模型找人工数据训练师。这其中又分为几个细分的方向,譬如数据分析、大模型生成结果判定、辅助大模型逻辑推理等等。
另一个方向则是CV(图像),存在已久,人们更加耳熟能详的是“2D拉框”和“3D拉框”,主要是满足滴滴、毫末、轻舟智航等这类车企,为其智能驾驶业务提供图像数据质检和标注帮助。
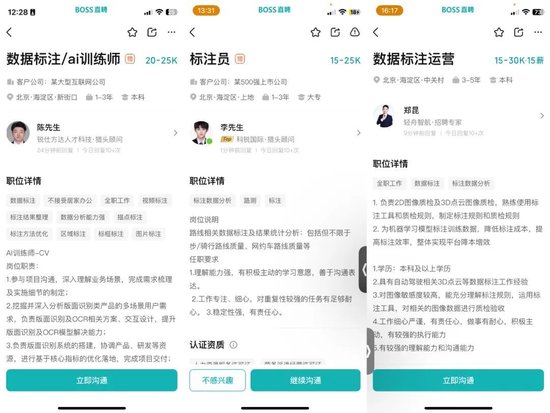
▲图源Boss直聘截图
‘自象限’观察发现,十一月是NLP方向数据标注的转折点,此前,百度、京东等大厂无论是校招还是社招,都仅开设了很少或压根没有AI数据标注岗位,招聘软件上也只是零星地开放了实习生的岗位,通常不设学历上限,大专学历封顶。
毫无征兆地突然冒出一批岗位需求,这背后或许与大模型厂商的研发受阻有关。多位行业人士曾向‘自象限’透露,截至目前,国内的大模型水平或许仅能达到GPT-3.5水平,发展的核心还是数据质量问题。
一边是国外OpenAI连放猛招,直逼GPT-5,一边是国内企业喊着“要落地”、“要用上大模型”,双重压力下,又用起了“人海战术”。
技术研发水平不够,人工能力来补齐,国内大模型厂商开始疯卷“AI数据标注员”,为大模型能力“飞升”再加一把燃料。

大厂卷精标,粗标“割韭菜”
事实上,数据标注并不是新鲜事儿,早已有之。以前的形式是粗标,主要表现为“拉框”,但现在粗标发展得乱了套:一是此前大厂粗标多为众包标注平台,工单分散,人员不专业,导致标注质量不行;二是随着大模型的精进,粗标变得越来越不够用,精标的地位由此直线上升。
针对粗标和精标的差异,某大厂员工解释道:“一般厂商的外包团队,能做标注,但他们就是按照框定的规则标注,如果出现规则之外的数据,标注就会存在通过率不高的情况来回反复,但是由工程师团队来做,特别是针对自动驾驶辅助驾驶等回传的数据,他们知道背后的原理,可能不会按照常规的思路标注,会带解决问题的思路来标注,可能需要跳出之前制定的标注规则,这样标注数据的质量会更高。”
大模型爆火,也为粗标刮起了一阵“新钱风”。
目前,粗标求职阵地已经从招聘软件转移到了快手等短视频平台。以快手为例,粗标求职热度与快递员并列,大量数据标注公司入驻快手,覆盖京津冀、长三角和珠三角地区。
▲图源快手截图
据‘自象限’了解,快手的直播招聘业务“快聘”曾在发布会中特别提到:“要解决数据标注职类线下招聘难,应聘者少的核心诉求问题 。”
落实到实处,快手从公司资质审核、流量扶持、公司推荐到数据标注职业推广都给予了支持,‘自象限’注意到在快手官方招聘直播间中,有时也在全天无间断地滚动地播报有关数据标注求职信息。
这一定程度上也成为了某些数据标注公司的“尚方宝剑”。在招聘时候,宣传之词毫无遮拦,“无需学历,上手即会,小学生都能做”,“拉一个框,打一个标签,就是半个毛”,“拉3000个150元,6000个300元,月入7000-8000洒洒水,只要手速够快”,极尽夸张之词。
但事实究竟如何呢?一万块钱能拿得如此轻松吗?
为探究真假,‘自象限’在快手报名联系上了一家热门数据标注公司。该公司声称与比亚迪、理想、小鹏、特斯拉等车企直接签单获得一手数据任务,且出示了大量的证书、凭证强调其正规性。入职后的主要任务就是接任务包,在图片上拉框、标注和打标签。

▲图源微信截图
总结下来,有几个基本点:打框按计件算钱,一个框价格在一毛到一毛五;薪资首月按周结,第二个月以后按月结算;新手小白需要先缴纳2580元培训费用,一年内工资累计达到1万,才能退还;平均七天左右学习培训时间就能上手做任务;分兼职和全职,兼职按框计算,全职线下坐班,另免费提供住宿;在其展示的员工工资截图中,月工资在5000-6000元不等。
但在黑猫投诉平台上,上述公司成为了数据标注投诉的重灾区。
一些投诉用户的经历与我们相吻合。综合用户的反馈,投诉主要集中在以下几个问题:第一,不会拉框需要先缴纳2580元费用,一年做拉框任务满一万元,但是出现了拒不退款的问题;第二,培训内容非常简单,且耗时长,耽误用户上岗;第三,不给通过和达标,总是卡拉框的合格率,最终影响收入;第四,态度豪横,无视用户的诉求,不处理、不退款。

▲图源黑猫投诉平台截图
以上的问题也只是冰山一角,‘自象限’虽然没有缴费报名成功,但在咨询后的一段时间内,也频繁地收到电话、微信的轮番轰炸,从早安到晚安,问候从未落下,还时不时地用其他员工的工资表进行挑逗、刺激。
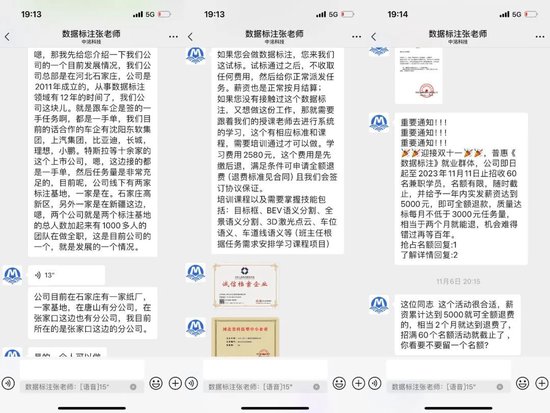
▲图源微信截图
一次严肃的数据标注求职,俨然沦为了一场“割韭菜”游戏,老老实实拉框的员工颗粒无收,反而是收培训费的数据标注公司赚得盆满钵满。
数据质量决定了大模型走得速度,即使是OpenAI也不例外。外媒报道称,OpenAI一方面找了多家知名的数据公司来数据标注,一方面也自己组建了一个几十名哲学博士团队来做数据质检。
大模型的根基在数据,数据质量直接决定了大模型进化的速度,从数据标注的乱象中,我们或许能一窥为什么中国大模型发展进度慢的原因,但既然大模型厂商们也意识到了数据标注的源头问题,离我们真正突破到GPT-4,或许也就不远了。
上一篇: 央视网:边输液边写作业,能理解但不支持
下一篇: 2024年艺考等高校招生将改革 教育部部署相关工作